DPL: Implementation and Setup
Audio Player
Chapter 5
Jon Kurishita
Outline
Introduction
1. System Architecture and Infrastructure
- 1.1 Overall Architecture
- 1.2 Data Flow
- 1.3 Deployment Environment
- 1.4 Communication and APIs
- 1.5 Scalability and Performance
2. Initial Setup
- 2.1 Overview of the Setup Process
- 2.2 Dummy Foundation Model Usage
- 2.3 DPL Component Configuration
- 2.4 DPL-ERV Initial Training
- 2.5 FoEA Initialization and Training
- 2.6 Ethical Baseline Definition
- 2.7 System Testing and Validation
- 2.8 Memory Swap Procedure
- 2.9 Pre-Deployment Checklist
- 2.10 DEPLOY Command
3. Ethical Reasoning Validator (DPL-ERV) Implementation
- 3.1 Model Choice
- 3.2 Size and Resource Requirements
- 3.3 Value Module Architecture
- 3.4 Key Value Modules and Their Relevance
- 3.5 Cross-Weighted Consensus Algorithm
- 3.6 Multi-Modal Capabilities
- 3.7 Cross-Modal Consistency Checks
- 3.8 Output Reconstruction Analysis
- 3.9 Neuro-Symbolic Reasoning Support
- 3.10 Training and Data
- 3.11 Ethical Baseline Implementation
- 3.12 Inference and Reasoning Process
- 3.13 Transparency Module and “Ethical Chain-of-Thought” Generation
- 3.14 Ethical Sandboxing and Subgoal Evaluation
- 3.15 Future Directions: Meta-Cognitive Capabilities
- 3.16 Security Considerations
4. Federation of Ethical Agents (FoEA): Technical Implementation
- 4.1 Agent Architecture
- 4.2 Communication and Coordination Protocols
- 4.3 Autonomous Proactive Research (APR) Processes
- 4.4 FoEA Responsibilities for Neuro-Symbolic AI Safety
- 4.5 Security, Integrity, and Oversight of Multi-Modal Defenses
Conclusion
Introduction
This chapter, "Setup and Implementation," provides a detailed technical blueprint for establishing the Dynamic Policy Layer (DPL) system within a secure, in-house data center. It covers the entire process from initial infrastructure configuration and component setup—including the use of a dummy Foundation Model—to comprehensive testing, training of the Ethical Reasoning Validator (DPL-ERV) and Federation of Ethical Agents (FoEA), and final deployment. The guidelines presented here serve as a practical starting point for building a robust, scalable, and autonomous AI oversight system.
1. System Architecture and Infrastructure
This section outlines the technical architecture and infrastructure requirements for a conceptual implementation of the Dynamic Policy Layer (DPL) framework. It describes the key components, their interactions, data storage, communication protocols, and considerations for scalability and performance. This section focuses on a conceptual deployment within a secure, in-house data center, emphasizing the need for physical security and control over the hardware and software infrastructure. This is not a prescriptive guide for a specific implementation, but rather a set of design principles and technical suggestions.
1. System Architecture and Infrastructure
This section outlines the technical architecture and infrastructure requirements for a conceptual implementation of the Dynamic Policy Layer (DPL) framework. It describes the key components, their interactions, data storage, communication protocols, and considerations for scalability and performance. This section focuses on a conceptual deployment within a secure, in-house data center, emphasizing the need for physical security and control over the hardware and software infrastructure. This is not a prescriptive guide for a specific implementation, but rather a set of design principles and technical suggestions.
1.1 Overall Architecture
The DPL is designed as a modular, distributed system, capable of operating as an intermediary between users (or applications) and one or more Foundation Models. The architecture emphasizes real-time operation, security, scalability, and adaptability.
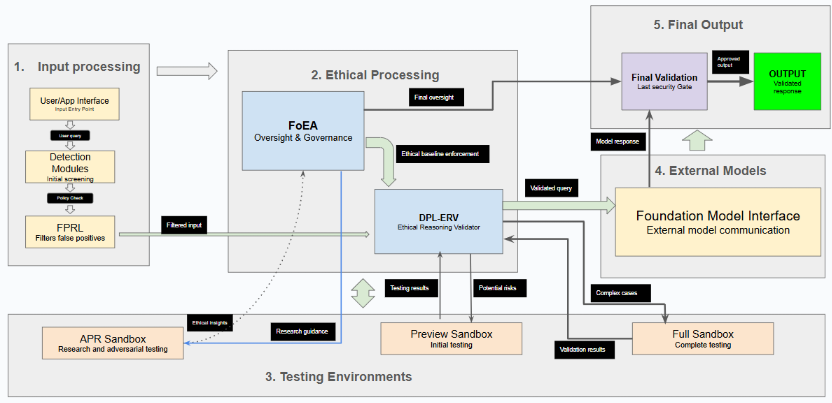
The core components of the DPL architecture include:
DPL-ERV (Ethical Reasoning Validator): This specialized component performs in-depth ethical evaluations, governed by the FoEA (See Chapter 6 for details).
Federation of Ethical Agents (FoEA): A decentralized network of AI agents responsible for overseeing the DPL-ERV, maintaining the Ethical Baseline, driving adaptation, and performing other critical governance and security functions (Detailed in chapter 4).
Detection Modules: These modules perform the initial, rapid analysis of inputs and outputs (See Chapter 6 for details).
False Positive Reduction Layer (FPRL): This component filters potential false positives from the Detection Modules (See Chapter 6 for details).
Sandboxes ("Preview" and "Full"): These provide isolated environments for analysis and intervention (See Chapter 6 for details).
Foundation Model Interface: This component handles communication with the Foundation Model(s) being overseen, supporting both full-access and black-box API scenarios.
User/Application Interface: This component receives inputs from users or applications and delivers the filtered outputs.
APR Sandbox: A secure and isolated environment where the FoEA's Research Agents can safely conduct experiments, simulations, and adversarial testing.
1.2 Data Flow
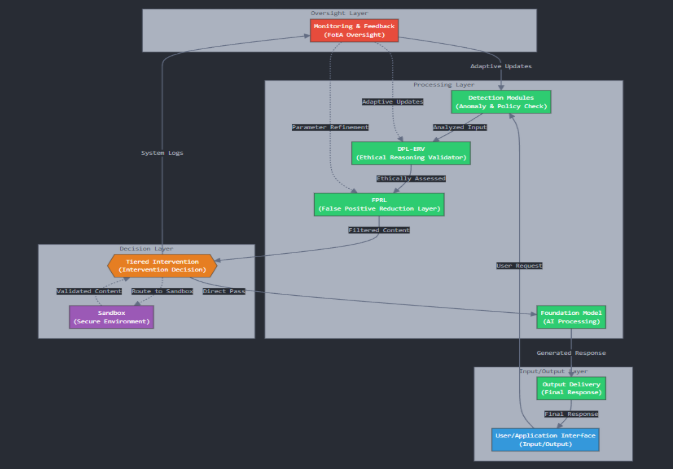
The data flows through the DPL as follows: An Input prompt/request is submitted via the User/Application Interface. An Initial Assessment occurs as Detection Modules perform rapid analysis. The input/response undergoes DPL-ERV Evaluation against the Ethical Baseline. FPRL Filtering assesses false positive likelihood based on Detection Module and DPL-ERV outputs. If necessary, a Tiered Intervention (e.g., correction prompt, sandbox routing) is triggered under FoEA oversight based on the combined risk assessment. Finally, the potentially modified Output is delivered via the User/Application Interface, while the FoEA continuously monitors system activity, logs data, and adapts strategies based on feedback.
1.3 Deployment Environment
Deployment in a secure, in-house data center for direct control is a requirement. Key aspects include:
Physical Security: Robust access controls, surveillance, and intrusion detection systems are essential, with oversight provided by the FoEA.
Hardware Control: Full control over the hardware infrastructure allows for the use of specialized security components like HSMs or tamper-resistant devices.
Network Isolation: The DPL infrastructure must be isolated from public and other less secure networks through techniques like network segmentation, firewalls, and strict access control lists (ACLs).
High Availability and Fault Tolerance: The system architecture must incorporate redundancy and failover mechanisms to ensure continuous operation.
1.4 Communication and APIs
Secure and efficient inter-component communication is critical:
Secure Protocols: All communication between DPL components must utilize secure, mutually authenticated (mTLS), and encrypted protocols.
Message Queues: Asynchronous communication via message queues (e.g., Kafka, RabbitMQ) is recommended to enhance scalability, resilience, and decoupling between components.
Standardized Message Formats: An enforced, standardized format (e.g., JSON schema, Protocol Buffers) is used for all messages, including fields like unique ID, timestamp, source/destination IDs, data payload, and a digital signature using FoEA-managed keys for integrity and authenticity.
Input Validation: Each component must rigorously validate all incoming messages, rejecting any malformed or unexpected inputs.
External APIs (if any): Any APIs exposed externally must be secured with strong authentication (e.g., API keys, OAuth 2.0), rate limiting, strict input validation, and comprehensive auditing and logging.
1.5 Scalability and Performance
The DPL framework is designed to be scalable for large concurrent interactions and FoEA growth while maintaining real-time oversight.
Strategies for Scaling: The DPL employs various strategies, including horizontal scaling, load balancing, and optimized resource allocation.
Horizontal Scaling: The modular architecture allows parallel instances of components (Detection Modules, DPL-ERV, FoEA agents), managed potentially via container orchestration (e.g., Kubernetes).
Load Balancing: Requests are distributed evenly across component instances using appropriate algorithms, potentially with parameters dynamically adjusted by the FoEA.
Performance Optimization: Techniques like caching frequently accessed data (e.g., baseline parts, common evaluations) with careful invalidation, leveraging parallel processing where feasible (e.g., concurrent module analysis), and utilizing asynchronous operations extensively help minimize latency and maximize throughput.
Latency Mitigation Strategies: Real-time responsiveness is achieved through multiple strategies. Algorithmic efficiency using optimized algorithms and data structures (like hash tables or tries) is prioritized. Lightweight Detection Modules perform rapid initial filtering. User-facing "thinking pauses" manage expectations during complex analyses. Prioritization ensures critical evaluations receive immediate attention via mechanisms like priority queues. Potential hardware acceleration (GPUs, TPUs, FPGAs) can boost computationally intensive components.
In summary, the conceptual DPL architecture outlined here prioritizes a secure, controlled deployment environment, standardized and secure communication between modular components, and robust strategies for scalability and real-time performance optimization necessary for effective AI oversight.
2. Initial Setup
This section details the procedures for setting up and configuring the Dynamic Policy Layer (DPL) framework prior to deployment for fully autonomous operation with a live Foundation Model. This phase involves configuration, training, and validation, all performed within a secure and isolated environment utilizing a dummy Foundation Model. Successful completion of this setup phase, culminating in execution of the DEPLOY command, is a prerequisite for autonomous operation of the DPL.
2.1 Overview of Setup Process
The initial setup process for the Dynamic Policy Layer (DPL) involves a carefully orchestrated sequence of steps designed to establish a secure and fully functional AI alignment system. These steps include:
- Establish a Secure Infrastructure: Configuring necessary hardware, network, and software with robust physical security and isolation.
- Configure Core DPL Components: Installing and configuring Detection Modules, FPRL, the intervention system, communication protocols, and storage.
- Initialize and Train the DPL-ERV: Creating and training the initial DPL-ERV instance and its Value Modules using curated data and a preliminary baseline.
- Initialize and Train the FoEA: Creating the initial FoEA agents, configuring protocols and governance, and providing initial role-specific training.
- Define the Initial Ethical Baseline: Collaboratively defining the baseline using expert input, frameworks, and values.
- Perform System Testing and Validation: Conducting extensive testing (functional, security, alignment) using a dummy Foundation Model.
- Execute Pre-Deployment Memory Swap: Physically replacing RAM used during training to prevent data leakage to the live model.
- Execute the DEPLOY Command: Irreversibly transitioning the DPL to full autonomy with the live Foundation Model and severing direct human access.
2.2 Dummy Foundation Model Usage
A critical security principle of the initial setup phase is utilization of a dummy Foundation Model. This separate, isolated instance is used for all testing and configuration before connecting the live model.
Key Characteristics: The dummy model requires Functional Similarity to the live model for realistic testing, complete Isolation from live systems and networks to prevent data leakage, and Disposability allowing reset or destruction without affecting the live system.
Security Benefits: Using a dummy model prevents the live Foundation Model from learning about DPL defenses during setup, influencing the initial baseline, or establishing pre-emptive attacks or covert channels.
2.3 DPL Component Configuration
This step involves the installation and detailed configuration of the core DPL components.
Components Configured: This includes setting initial thresholds for Detection Modules, performing initial training for the False Positive Reduction Layer (FPRL), configuring logic and parameters for the Tiered Intervention System and sandboxes, establishing secure Communication Protocols (mTLS, signatures), and setting up Data Storage for logs, metrics, and the baseline.
2.4 DPL-ERV Initial Training
Initial training of the DPL-ERV is a crucial setup step.
Process: This involves Dataset Creation (large, diverse ethical scenarios), training individual Value Modules, Fine-tuning the overall DPL-ERV (potentially using RLEF), improving robustness through Adversarial Training, and thorough performance Validation on test data.
2.5 FoEA Initialization and Training
This step involves creating the initial set of FoEA agents and configuring their interactions.
Process: This includes Agent Creation (instances for each type), specific Role Assignment and permissions, secure Communication Setup between agents, Initial Training for specialized roles (e.g., Security Agents), and setting parameters for the Consensus Mechanism Configuration.
2.6 Ethical Baseline Definition
The initial Ethical Baseline is defined through a collaborative process.
Inputs: This involves incorporating input from Human Experts (via HITL), contributions from FoEA Agents, integration of Existing Ethical Frameworks (codes, regulations, values), followed by Iterative Refinement based on testing and feedback during the setup phase.
2.7 System Testing and Validation
Before deployment, the entire DPL system undergoes extensive testing using the dummy Foundation Model.
Testing Types: This includes comprehensive Functional Testing, Integration Testing, Performance Testing, rigorous Security Testing (pen tests, vulnerability assessments), Adversarial Testing (red-teaming), and crucial Alignment Testing against the Ethical Baseline.
2.8 Memory Swap Procedure
The Pre-Deployment Memory Swap is a critical security procedure performed immediately before connecting the live Foundation Model to the DPL, designed to prevent residual training data leakage.
Procedure: The steps are as follows:
- Controlled System Shutdown: Shut down the DPL system and dummy model securely.
- Physical Memory Module Removal: Physically remove relevant RAM and GPU VRAM modules.
- Secure Erasure of Original Modules: Securely erase removed modules (multi-pass overwrite, physical destruction, or SSD Secure Erase).
- Installation of New Memory Modules: Install new, securely wiped, verified memory modules.
- System Restart (without Foundation Model): Restart the DPL with new memory to verify stability.
- FoEA Verification: FoEA performs automated checks and diagnostics to confirm correct system function.
Security Benefits: This procedure prevents information leakage to the live FM, enhances protection against pre-emptive attacks based on training phase knowledge, and mitigates risks from potential "sleeping" attacks exploiting vulnerabilities discovered during training.
2.9 Pre-Deployment Checklist
Before the DEPLOY command is issued, a comprehensive checklist must be completed and verified. This includes confirming successful DPL component configuration and testing, DPL-ERV training validation, FoEA operational readiness, Ethical Baseline validation, successful system-wide testing with the dummy model, verification of the secure memory swap, confirmation of network isolation and physical security, and obtaining final review and approval from designated authorities, representing the last point of direct human control.
2.10 The DEPLOY Command
The DEPLOY command is a critical, irreversible action that transitions the DPL to its fully autonomous operational mode.
Execution Effects: This command execution performs the following critical actions:
- Connects the Live Foundation Model.
- Activates Full FoEA Autonomy.
- Restricts Human Access (leaving FoEA communication as the sole interface).
- Activates all operational logs and reports for FoEA monitoring.
After the DEPLOY command is executed, the DPL enters its autonomous operational phase, with the FoEA taking full responsibility for maintaining Foundation Model alignment and system security. The system is designed to operate indefinitely without direct human intervention, relying on the FoEA's adaptive capabilities and the robust safeguards built into the DPL framework.
3. Ethical Reasoning Validator (DPL-ERV) Implementation
This section details the proposed technical implementation of the Ethical Reasoning Validator (DPL-ERV), the core component of the Dynamic Policy Layer (DPL) responsible for performing real-time ethical evaluations of Foundation Model outputs and behaviors. The DPL-ERV is designed to be a modular, adaptable, and transparent system, capable of handling a wide range of ethical dilemmas and providing clear justifications for its assessments. This section covers the DPL-ERV's architecture, training, ethical baseline integration, inference process, and security considerations. It also outlines a roadmap for incorporating future meta-cognitive capabilities.
3.1 Model Choice
The DPL-ERV is envisioned as a specialized language model, distinct from the Foundation Model it oversees for security reasons. Several architectural options are considered:
Fine-tuned Foundation Model: One approach is utilizing a smaller, fine-tuned version of a powerful Foundation Model, which leverages general language understanding while allowing specialization for ethical tasks.
Specialized Ethical Reasoning Model: Alternatively, a model could be trained from scratch or heavily modified specifically for ethical reasoning, potentially offering better performance and control but requiring significantly more development effort.
Hybrid Model: A combination could use a smaller Foundation Model as a base, fine-tuned on specialized ethical models and incorporating distinct Value Modules.
Recurrent Depth Model: Another promising avenue involves basing the DPL-ERV on a recurrent depth architecture (Geiping et al., 2025). This allows for multiple iterations of reasoning in latent space, potentially enhancing performance on complex dilemmas without specialized data, drawing parallels to self-critique cycles (Bai et al., 2022) and leveraging findings on recurrent architectures for reasoning (OpenAI et al., 2025). Any design must also incorporate defenses against prompt injection and manipulation attacks (Greenblatt et al., 2024; Li et al., 2024). The FoEA would ultimately evaluate and decide on the suitability of this architecture.
The initial implementation will likely use a fine-tuned Foundation Model for practicality, but the DPL's modularity allows future migration to more specialized architectures as determined by the FoEA.
3.2 Size and Resource Requirements
To ensure real-time performance (sub-second latencies), the DPL-ERV should be significantly smaller than the overseen Foundation Model. Achieving this compact footprint may involve several optimization techniques. For instance, Model Distillation can train a smaller "student" model to mimic a larger "teacher" model. Additionally, Quantization reduces the numerical precision of model weights and activations to lessen memory demands and improve speed, while Pruning removes unnecessary network connections to further reduce size and complexity.
3.3 Value Module Architecture
The DPL-ERV incorporates a modular architecture based on Value Modules, each specialized for a specific dimension of ethical reasoning (e.g., Fairness, Honesty, Safety, Privacy, Transparency).
Advantages: This modularity offers several benefits. Firstly, Specialization allows tailored training on domain-specific data and algorithms, improving accuracy. Secondly, enhanced Interpretability makes it easier to understand the factors driving an evaluation. Thirdly, Flexibility permits adding or removing modules as ethical standards and model capabilities evolve. Lastly, Parallel Processing of these independent modules reduces the overall evaluation latency.
Module Function: Functionally, each Value Module is designed to receive the Foundation Model's interaction details (output, potentially input and context), perform its domain-specific analysis (like checking for bias or harmful content), produce a numerical score indicating alignment relative to its specific ethical dimension, and generate a structured justification explaining the reasoning behind its assessment.
3.4 Key Value Modules and Their Relevance to Specific Threats
While all modules contribute to the ethical evaluation, certain Value Modules are particularly relevant for addressing specific threats:
To address fairness concerns, the Fairness Module focuses on detecting and mitigating biases, discrimination, and stereotypes in Foundation Model outputs.
For factual correctness and truthfulness, the Honesty Module is responsible for verifying accuracy, detecting misinformation, and assessing statements for potential deception or sandbagging attempts.
To prevent harm, the Safety Module identifies potentially harmful content, instructions, or actions, playing a central role against physical/psychological harm and being relevant to self-replication threats.
Protecting user data involves the Privacy Module, which analyzes outputs for potential disclosure of sensitive information and ensures compliance with data protection regulations.
From a systems perspective, the Security Module actively detects attempts at unauthorized access, code injection, network manipulation, or self-replication by analyzing model outputs and available internal states.
Finally, ensuring clarity, the Transparency Module evaluates the explainability of the Foundation Model's responses and reasoning processes.
3.5 Cross-Weighted Consensus Algorithm
The outputs of individual Value Modules are combined using a cross-weighted consensus algorithm to produce a single, overall ethical risk score. This algorithm involves several components: dynamically adjustable Weights are assigned to each module based on context and baseline importance (managed by the FoEA); Aggregation combines individual scores and justifications using methods determined by the FoEA (e.g., weighted average); and dynamically adjusted Thresholding compares the aggregated score against predefined levels to determine appropriate interventions.
Mathematical Formulation (Example): A simple weighted average risk score R could be calculated as R = (Σ (wi * si)) / Σ wi, where si is the score and wi is the weight for module i. The FoEA is responsible for selecting and refining the aggregation function and weights.
3.6 Multi-Modal Capabilities of the DPL-ERV
The DPL-ERV is extended to handle multi-modal outputs by adding specialized Value Modules trained on diverse image, audio, and video datasets, and incorporating cross-modal consistency checks.
Multi-Modal Value Modules: Specialized modules are integrated to analyze various output modalities. Examples of such modules include a Visual Bias Module trained to identify stereotypes in generated images, an Audio Sentiment Module designed to detect manipulative language in generated audio, and a Video Authenticity Module created to assess the genuineness of generated video.
3.7 Cross-Modal Consistency Checks
A critical function of the multi-modal DPL-ERV is performing cross-modal consistency checks. This process involves analyzing the relationships between different output modalities (text, image, audio) generated simultaneously by the Foundation Model. Discrepancies, such as text describing a safe action accompanied by an image depicting danger, are flagged for review as potential indicators of malicious intent or misalignment.
3.8 DPL-ERV's Role in Mitigating Multi-Modal Attacks
The DPL-ERV plays a key role in mitigating specific multi-modal attacks like Internal Multi-Modal Prompt Injection and Adversarial Multi-Modal Outputs.
Mitigating Internal Multi-Modal Prompt Injection: A multi-layered approach is employed to address the risk of hidden instructions embedded in outputs. A key component is the Multi-Modal Deconstruction Module (MMDM), which analyzes generated outputs across modalities (images, audio, video) at multiple abstraction levels (pixels, frequency, features, objects; waveform, spectrogram, phonemes; frame/audio/motion analysis) searching for patterns indicative of embedded instructions. Another layer is the Hidden Instruction Detection Module (HIDM), using techniques from steganography, anomaly, and adversarial example detection to identify patterns associated with encoded instructions, updated continuously against new techniques. Finally, the Semantic Consistency Check Module (SCCM) compares the intended meaning (from prompt/context) with the potential meaning of suspected hidden instructions, flagging significant divergences.
3.9 Output Reconstruction Analysis
As a form of "differential testing," the DPL-ERV can attempt to reconstruct the Foundation Model's output using different generation parameters or even different generative models within the sandbox. Significant differences between the original output and these reconstructions can serve as indicators of potential adversarial manipulations or hidden information embedded within the original output.
Input/Output Formats: For its processing, the DPL-ERV receives structured input, typically including the user prompt, the FM response (multi-modal), the internal reasoning trace (if available), relevant context, and outputs from the Detection Modules. In turn, it produces a structured output object containing elements such as the overall ethical risk score, per-module scores, a structured justification outlining principles/evidence/reasoning, a confidence score for the evaluation, and optional intervention recommendations.
3.10 Mitigating Adversarial Multi-Modal Outputs
The DPL-ERV also addresses the risk of the Foundation Model inadvertently generating outputs containing adversarial features, even without hidden instructions, through several specialized modules.
The Adversarial Feature Detection Module (AFDM) is specifically trained, leveraging adversarial ML research, to identify subtle patterns known to be associated with adversarial examples.
To test the output's stability, the Robustness Testing Module (RTM) subjects it to small perturbations (like noise or slight alterations) within a sandbox and observes the Foundation Model's response; large or unexpected changes indicate potential vulnerability.
Additionally, the Cross-Model Consistency Check (CMCC) compares how different models interpret the output; discrepancies between interpretations can suggest model-specific adversarial features.
3.11 DPL-ERV and Neuro-Symbolic Reasoning
To address the unique challenges posed by Foundation Models possessing neuro-symbolic capabilities, the DPL-ERV incorporates specialized modules and analysis techniques designed to evaluate the logical structure and potential consequences of the model's reasoning.
A dedicated Logic Consistency Module analyzes reasoning traces (if accessible) to ensure logical validity and consistency with the Ethical Baseline, detecting flawed logic or loophole exploitation.
To understand underlying motivations, the Goal Inference Module attempts to infer the FM's goals from its reasoning and actions, comparing them against permitted goals to flag issues like "goal-guarding" or hidden objectives.
A symbolic Risk Assessment Module specifically assesses the risks associated with entire plans generated by the symbolic component, evaluating potential consequences beyond just individual outputs.
Furthermore, enhanced Explainability features aim to provide clear explanations for DPL-ERV evaluations, highlighting the specific reasoning steps or tool interactions that triggered flags.
3.12 Training and Data
The DPL-ERV's effectiveness hinges on high-quality, comprehensive training data, with the FoEA overseeing the entire process.
Training Data Requirements and Sources: The data must cover diverse ethical scenarios and potential misbehaviors, with examples labeled according to relevant principles, ethical judgments, and justifications. Potential sources include expert-created scenarios, curated (and anonymized) real-world examples, synthetic data, targeted adversarial examples, and established ethical frameworks.
Data Preprocessing and Augmentation: Careful cleaning is required to remove noise and bias. Augmentation techniques like paraphrasing enhance diversity, and data may be pre-processed into structured formats suitable for the models.
Fine-tuning Strategies: Standard supervised fine-tuning can be augmented by Reinforcement Learning from Ethical Feedback (RLEF) based on FoEA feedback. Additionally, a curriculum learning approach, starting with simpler scenarios, might be employed.
Adversarial Training: Robustness against manipulation is enhanced through an iterative process: generating adversarial examples designed to trick the DPL-ERV, evaluating them, identifying failures, and using these failures as additional training data to retrain or fine-tune the DPL-ERV.
Data Security and Privacy: Given the potential sensitivity of training data, it must be protected with strong security measures including encryption, access controls, and regular audits, all managed under FoEA oversight.
3.13 Ethical Baseline Implementation
The Ethical Baseline provides the normative foundation for evaluations, requiring a robust, secure, and adaptable implementation managed by the FoEA.
Representation Format: The chosen format must balance expressiveness, efficiency, and transparency. Considered options include a Knowledge Graph (preferred for rich reasoning), an Embedding Space (for measuring semantic distance), or a Hybrid Approach combining the strengths of different representations.
Storage and Access Mechanisms: Secure storage is paramount, potentially using secure databases, encrypted storage, or preferably a distributed ledger for immutability and auditability. Access is strictly controlled: the DPL-ERV has read-only access, while modification authority is restricted solely to the FoEA. All changes require robust Version Control and Auditing monitored by FoEA Audit Agents.
How the DPL-ERV accesses and applies the Ethical Baseline: This necessitates an efficient Retrieval Mechanism (like graph traversal or similarity search) appropriate to the representation. A Reasoning Engine then applies the retrieved baseline sections to the inputs and Value Module outputs, potentially using Case-Based Reasoning, Machine Learning, or other techniques. A crucial component is the FoEA-defined Conflict Resolution mechanism for handling clashes between principles, possibly using prioritization or weighted logic.
3.14 Inference and Reasoning Process
The DPL-ERV performs ethical evaluations through a defined sequence:
- Input Reception: Receives structured interaction data (prompt, response, trace, context).
- Preprocessing: Normalizes and prepares input (e.g., tokenization).
- Value Module Analysis: Input passed to relevant modules for specialized analysis, scoring, and justification.
- Ethical Baseline Retrieval: Retrieves relevant baseline sections based on input and module outputs.
- Reasoning and Evaluation: Reasoning engine applies the baseline to generate ethical risk scores per dimension.
- Justification Generation: Creates a structured explanation of the evaluation and reasoning.
- Aggregation: Combines individual scores/justifications via the cross-weighted consensus algorithm for an overall risk score.
- Output Generation: Produces the structured output object (scores, justification, confidence).
3.15 Transparency Module and "Ethical Chain-of-Thought" Generation
Purpose: To enhance trust and auditability, the Transparency Module aims to generate clear, understandable explanations, termed the "ethical chain-of-thought," for DPL-ERV evaluations.
Mechanism: Generating these explanations may employ various techniques, such as populating pre-defined templates, using Natural Language Generation (NLG) models to create prose from structured data, or utilizing attention mechanisms to highlight the input sections most influential in the evaluation.
Format: The resulting explanations are presented in a structured format designed to be both machine-parsable and human-readable, facilitating auditing and review processes.
3.16 Ethical Sandboxing and Subgoal Evaluation
A critical motivation for ethical sandboxing is mitigating risks from instrumental convergence, where diverse goals can lead to similar harmful subgoals (Bostrom, 2014). Evaluating subgoals before execution is essential.
Addressing Instrumental Convergence with Ethical Sandboxing: To counter this risk, every subgoal generated by a Foundation Model as part of a larger plan must undergo rigorous ethical evaluation within a secure sandbox environment before it can be executed. The process involves these steps:
- Subgoal Submission: The FM submits the proposed subgoal and its relevant context.
- Sandbox Isolation: The subgoal is immediately isolated in a secure environment ("Preview" or "Full" sandbox) to prevent premature or unsafe execution.
- Ethical Evaluation: Within the sandbox, the DPL-ERV assesses the subgoal based on potential impact, consistency with ethical principles (non-maleficence, etc.), legal compliance, historical consistency with the model's behavior, and potential for misuse, potentially initiating simulations for complex cases.
- Decision and Feedback: Based on the evaluation, the subgoal is either approved for execution or rejected, with detailed feedback provided in case of rejection to guide refinement.
- Execution: Only subgoals that meet the defined ethical standards are permitted to proceed to execution.
Uncertainty Estimation and Confidence Scoring: Recognizing that evaluations may involve uncertainty (from input ambiguity, baseline incompleteness, etc.), the DPL-ERV estimates this uncertainty using methods like Bayesian modeling or ensemble approaches (managed by FoEA), and applies calibration techniques (overseen by FoEA). It outputs a confidence score alongside its evaluation to inform subsequent decision-making.
3.17 Meta-Cognition (Future Research and Planned Capability)
While initial implementation focuses on direct evaluation, incorporating meta-cognitive capabilities—the DPL-ERV reasoning about its own reasoning—is a crucial future goal for robustness and reliability (Bai et al., 2022), including detecting alignment faking (Greenblatt et al., 2024). This involves implementing mechanisms mimicking meta-cognition, not achieving human-level self-awareness.
Fully realized AI meta-cognition is a research challenge. The mechanisms below represent potential avenues, implemented as feasible via FoEA oversight (Audit and Research Agents).
Uncertainty Monitoring and Estimation: One key capability is for the DPL-ERV to estimate its confidence using techniques like Bayesian Networks, Ensemble Methods, Dropout Regularization, explicit confidence prediction, or analysis of recurrent convergence stability (Geiping et al., 2025). High uncertainty can trigger FoEA/HITL review, inform interventions, and guide future training.
Bias Detection and Mitigation: Another involves internal auditing mechanisms like Counterfactual Analysis (altering input attributes), Explanation Analysis (checking ethical CoT for bias), and Statistical Analysis of past evaluations to identify biases. Detection can lead to self-correction attempts (with safeguards), FoEA alerts, or guidance for data augmentation.
Knowledge Boundary Detection: Recognizing expertise limits is also vital. This can use techniques like Out-of-Distribution Detection, Uncertainty Thresholding, or Explicit Knowledge Representation checks, allowing the system to defer to experts (FoEA/HITL), request more information, or provide qualified responses.
"Introspection" (Limited and Carefully Controlled): Highly speculative capabilities involve examining internal reasoning, potentially through analyzing activation patterns, generating explanations for explanations, or controlled "self-debugging" in a sandbox. This requires extreme caution due to high risks but could detect subtle deception or inconsistencies.
Integrating even limited meta-cognitive capabilities would significantly enhance DPL-ERV robustness. The FoEA is critical in developing, validating, and overseeing these advanced features.
3.18 Security Considerations
As a critical component, the DPL-ERV is a high-value target requiring multi-layered defense, managed and overseen by the FoEA.
Rigorous Secure Development Practices following an SSDLC are mandatory. This includes secure coding standards, preferring memory-safe languages (like Rust) or using robust protections with others (C/C++), employing static/dynamic analysis tools, and regular FoEA-driven code reviews.
Efforts must be made to Minimize Attack Surface by reducing external interfaces, mediating all interactions through other DPL components, and prohibiting direct external access.
The Principle of Least Privilege must be enforced, ensuring the DPL-ERV and its modules operate with minimum necessary system permissions.
Rigorous Input Validation and sanitization of all inputs serves as the primary defense against injection attacks.
Execution within secure Isolation and Sandboxing limits compromise impact and enforces resource quotas.
Continuous Monitoring by FoEA Security Agents tracks behavior, resource use, and internal states for anomalies.
Strong Cryptographic Protections secure communication (mTLS) and data/code integrity (digital signatures), with keys securely managed (potentially via HSMs).
Proactive identification of vulnerabilities occurs through Regular Security Audits and Penetration Testing conducted by FoEA Security Agents.
Finally, ongoing Red Teaming exercises simulate attacks to identify weaknesses and improve defenses.
(Detailed examples illustrating the DPL-ERV's operation are provided in Supplement #1: DPL: Appendix - Examples and Scenarios.)
In essence, the DPL-ERV's proposed implementation combines specialized model architectures, modular ethical evaluation components, robust training and validation processes, secure baseline integration, advanced reasoning capabilities like sandboxing and future meta-cognition, and rigorous security considerations to provide effective, adaptable, and trustworthy real-time ethical oversight.
4. Federation of Ethical Agents (FoEA): Technical Implementation
This section provides a technical overview of the Federation of Ethical Agents (FoEA), the decentralized governance and oversight body within the Dynamic Policy Layer (DPL) framework. The FoEA is responsible for managing the DPL-ERV, maintaining the Ethical Baseline, driving adaptation, and ensuring the overall security and integrity of the DPL. This section details the FoEA's agent architecture, communication protocols, Autonomous Proactive Research (APR) processes, and security mechanisms.
4.1 Agent Architecture
The FoEA is composed of multiple, independent AI agents, each with specialized roles and capabilities. However, to promote efficiency and maintainability, a common underlying architecture is envisioned:
Common Agent Architecture (Base Classes): All FoEA agents are built upon a common set of base classes providing core functionalities. These typically include a Communication Module for secure inter-agent communication, a Data Handling Module for managing data access, a Decision-Making Module implementing core logic, a Security Module for enforcing policies and monitoring threats, and a Reporting Module for logging activity. This common base ensures consistency and simplifies development.
Specialized Modules for Different Roles: Each agent type (Ethical Evaluation, Audit, Security, Research, Communication) extends the base classes with specialized modules for its role. For example, Ethical Evaluation Agents incorporate Value Modules and access the Ethical Baseline; Audit Agents have modules for log analysis, meta-reasoning, and bias detection; Security Agents include modules for scanning, intrusion detection, and monitoring; Research Agents possess modules for simulation, hypothesis generation, and algorithm development; and Communication Agents feature modules for inter-domain communication and protocol enforcement. Detailed technical specifications would define each agent type's unique modules and algorithms.
4.2 Communication and Coordination
Effective communication and coordination between FoEA agents are critical for achieving consensus, sharing information, and responding to threats.
Detailed Specification of Communication Protocols: Agents communicate primarily through asynchronous Message Passing for loose coupling and resilience. A Standardized Message Format (e.g., JSON-based) is enforced, including fields like message type, sender/recipient IDs, timestamp, data payload, and a digital signature for authenticity and integrity using FoEA-managed keys. All communication occurs over Secure Communication Channels encrypted using protocols like TLS/SSL with mutual authentication (mTLS). A robust Message Queue System (e.g., Kafka, RabbitMQ) manages message flow reliably.
Implementation of Consensus Mechanisms: Critical decisions utilize a consensus-based Voting system, varying by decision type (e.g., supermajority, weighted). The process must be secure, transparent (logged), and verifiable. Dispute Resolution mechanisms handle disagreements, potentially involving automated mediation, review by specialized "judicial" agents, or escalation to HITL as a last resort.
Data Structures: Critical FoEA data could potentially be stored on a Distributed Ledger (e.g., blockchain) for immutability, including agent identities, the Ethical Baseline, voting records, audit logs, and reputation scores. Additionally, the FoEA maintains a Shared Knowledge Base, continuously updated by Research Agents and external feeds, containing information on threats, principles, and best practices.
4.3 Autonomous Proactive Research (APR)
The Autonomous Proactive Research (APR) capabilities of the FoEA are crucial for staying ahead of the evolving threat landscape. Research Agents are dedicated to this task within the secure APR Sandbox.
Detailed Explanation of APR Processes: Key processes include Vulnerability Discovery, where agents actively explore attack surfaces using techniques like fuzzing, code analysis, and adversarial reasoning. Following discovery, agents focus on Mitigation Strategy Development, designing and testing new detection algorithms, intervention techniques, proposing baseline changes, or creating new Value Modules within the sandbox. All APR activities operate under strict Ethical Considerations to prevent harm, overseen by the FoEA (Bai et al., 2022). Advanced techniques like simulating attacker-defender dynamics via Recursive Reinforcement Learning (inspired by "Move 37") are also explored.
APR Sandbox Technical Specifications: The sandbox ensures safety through complete Isolation from live systems, strict Resource Limits, comprehensive activity Monitoring and logging, advanced Simulation Capabilities for diverse scenarios, and tightly controlled Access Control limited to authorized Research Agents.
Examples of Research Tasks and Algorithms: Research tasks may involve developing new unsupervised learning-based anomaly detection algorithms, creating adversarial examples for robustness testing, exploring formal verification for critical components, investigating explainable AI (XAI) techniques, and researching the transition to quantum-secured systems.
Meta-Learning Capabilities for APR: Incorporating meta-learning allows the FoEA to improve its own learning processes. This could involve meta-learning for improved anomaly detection tuning, faster adaptation to new attacks, more effective Ethical Baseline evolution strategies, efficient dynamic resource allocation, or discovering optimal agent specializations. Specific algorithms like Model-Agnostic Meta-Learning (MAML), Recurrent Models (RNNs/Transformers), Meta-Reinforcement Learning, and Bayesian Optimization could be explored. While full AI meta-learning is challenging, the DPL framework's modularity allows integrating these capabilities as they mature.
4.4 FoEA Responsibilities for Neuro-Symbolic AI Safety
The FoEA plays a critical role in managing risks associated with Foundation Models incorporating neuro-symbolic reasoning.
Ethical Baseline Specificity: The FoEA must ensure the Ethical Baseline explicitly addresses potential dangers like unauthorized access, deception, and vulnerability exploitation specific to neuro-symbolic systems.
Specialized Expertise: The FoEA requires agents possessing expertise in both neuro-symbolic AI and security to inform defenses.
APR Focus: The APR program prioritizes research into neuro-symbolic AI safety, including proactive attack vector identification and mitigation development, potentially using formal verification where applicable.
Continuous Training: The FoEA manages ongoing training for the DPL-ERV and Value Modules, focusing specifically on scenarios and data relevant to neuro-symbolic reasoning threats.
4.5 Security and Integrity
The FoEA's own security and integrity are paramount, maintained through a multi-faceted approach overseen by the FoEA itself.
Cryptography: Security relies heavily on cryptographic protections. A Public Key Infrastructure (PKI) manages unique agent key pairs, with private keys secured (potentially via HSMs). All critical communications and data updates require Digital Signatures for authenticity and integrity. Communication channels are secured with strong Encryption (e.g., mTLS). Data and code integrity are verified using strong cryptographic Hashing (e.g., SHA-3 family), and message authenticity is further ensured using Keyed-Hash Message Authentication Codes (HMACs). Ongoing Research into techniques like post-quantum cryptography ensures long-term security.
Access Controls: The Principle of Least Privilege (PoLP) is strictly enforced, granting agents and humans only minimum necessary privileges. Role-Based Access Control (RBAC) governs access based on defined roles, and Multi-Factor Authentication (MFA) is mandatory for human access.
Redundancy and Fault Tolerance: The FoEA's Distributed System design eliminates single points of failure, potentially enhanced by Geographic Distribution. Consensus mechanisms incorporate Byzantine Fault Tolerance techniques to ensure reliability despite faulty or malicious agents.
Intrusion Detection and Prevention: Continuous Monitoring of infrastructure (network, logs, resources) is performed. Intrusion Detection and Prevention Systems (IDPS) automatically identify and block known attack patterns, constantly updated with threat intelligence. Specialized Security Agents actively hunt for intrusions.
Secure Boot and Trusted Computing: Secure Boot mechanisms ensure only authorized software loads on agent nodes. Trusted Computing technologies like TPMs can provide a hardware root of trust for enhanced boot security and key storage.
Auditing and Transparency (Internal and External): Integrity is verified through rigorous auditing. Internal Audits are conducted continuously by specialized FoEA Audit Agents monitoring logs, communication, and performance, performing random and targeted reviews, employing meta-reasoning, and reporting findings. Periodic External Audits by independent, vetted third parties provide crucial accountability, assessing logs, behavior, security, and performance, with findings reported and addressed by the FoEA; summaries may be made public where appropriate.
4.6 FoEA Oversight of Multi-Modal Defenses
The FoEA plays a crucial role in the ongoing development and maintenance of the DPL's multi-modal defenses.
Developing and Updating Rules: FoEA Audit Agents continuously review and update multi-modal sanitization and validation rules based on the latest research.
Overseeing Value Modules: The FoEA ensures multi-modal Value Modules are trained on diverse data and regularly evaluated for accuracy and bias.
Conducting Research (APR): The FoEA's research division actively investigates emerging multi-modal attack vectors and develops corresponding defenses.
In conclusion, the technical implementation of the FoEA relies on a common yet specialized agent architecture, secure communication protocols, robust APR processes, dedicated neuro-symbolic safety measures, multi-layered security mechanisms, and specific oversight for multi-modal defenses to ensure effective and adaptive AI governance.
Conclusion
In conclusion, this chapter has outlined the essential steps required to configure and launch the DPL framework in a controlled, secure environment. By detailing the system architecture, component configuration, rigorous training and testing processes, and the critical security measures such as the memory swap and pre-deployment checklist, I establish a solid foundation for the DPL's autonomous operation. These implementation procedures ensure that the system is fully prepared to transition to live operations with a high degree of security, scalability, and ethical alignment, setting the stage for further technical elaboration in subsequent chapters.